
How to Streamline Onboarding Processes for Global Teams
Feb 14, 2026


Working with colleagues across different time zones brings unique hurdles, especially when unexpected issues arise and require immediate responses. When a technical problem or major market change occurs, remote team members may experience a sense of isolation if they lack clear guidance. Establishing well-defined action steps and assigning responsibilities before emergencies happen helps everyone stay composed and coordinated. This guide presents a straightforward approach to getting ready, managing incidents, and assessing outcomes. You will find practical examples drawn from real situations, designed to suit teams spread out in home offices or sharing co-working spaces, making complex challenges easier to handle together.
Readers will find checklists, tool tips, and practices proven in companies with hundreds of staff in multiple countries. Each section stays focused on plain directions and real numbers, such as cutting incident response time by 40% in under three months. You’ll see how to set up a standard plan, choose the right channels, train teams with practice runs, and collect honest feedback to sharpen future efforts.
Every crisis plan must start with clear purpose. Define the scenarios that matter: data loss, service outages, severe weather, cyber breaches, or health emergencies. List each scenario with a one-line description and a worst-case impact rating on a scale from 1 to 5. This scale helps you decide where to focus resources first.
Team members need a shared understanding of key objectives. Aim for three main goals: fast reaction time, transparent updates, and a unified procedure. Set a target to send the first status update within 15 minutes of an incident report. Track progress using a simple dashboard that logs steps taken, time stamps, and next actions.
Remote teams succeed when they avoid duplicate work. A single playbook ensures everyone acts on the same page. Use color-coded labels—green for stable, yellow for caution, red for critical. Each label must match a clear set of actions without room for guesswork.
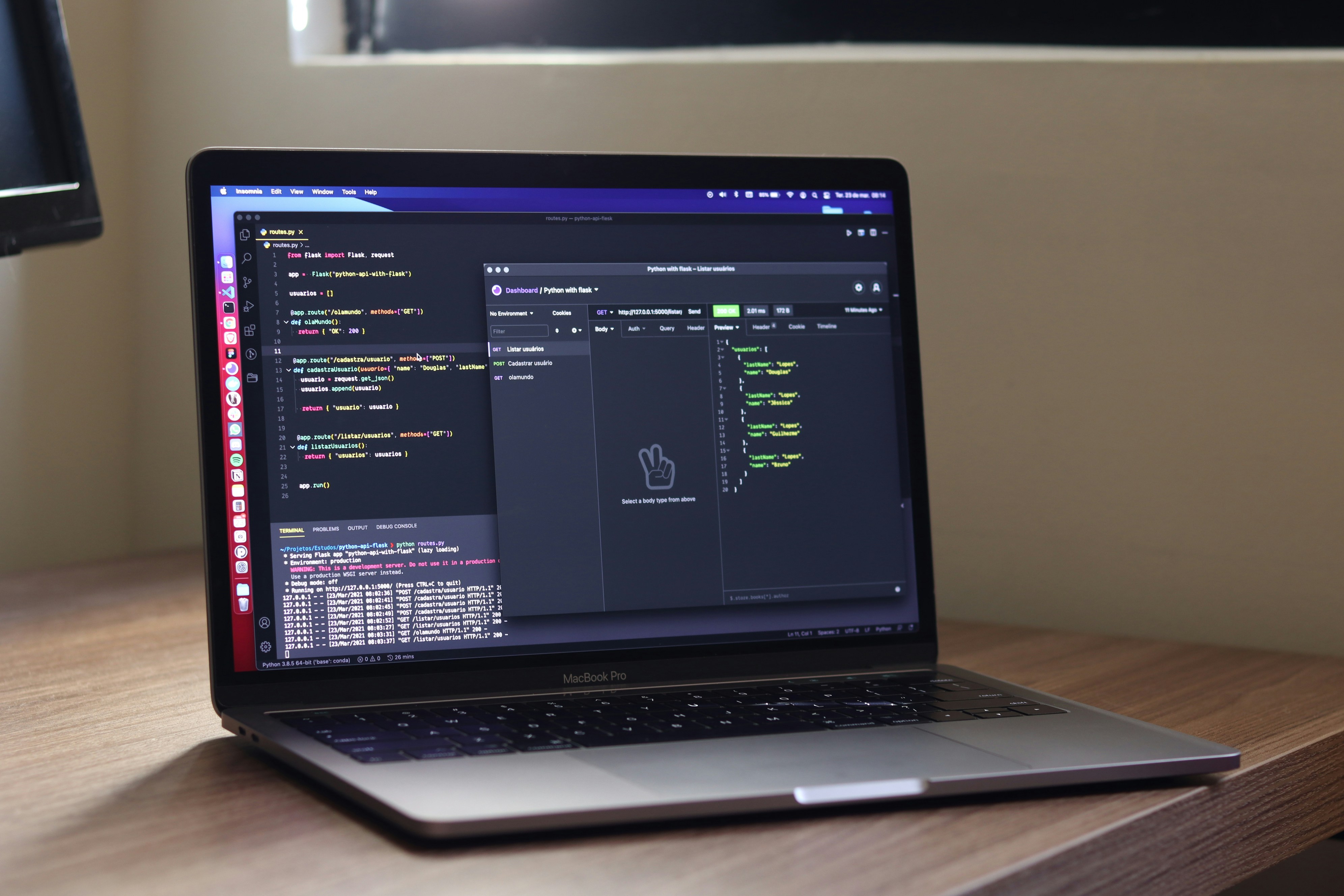
Publish the protocol in a format that’s easy to scan on a mobile device. A plain-text summary works well alongside the full flowchart. Update the summary whenever you change one step. This habit reduces confusion and keeps everyone aligned, whether they see the full chart or only the quick guide.
A reliable line of contact guarantees that no one misses critical alerts. Teams using a single chat thread report decision-making 35% faster than those juggling multiple channels. Limit noise by muting non-crisis topics in the crisis channel. Keep it strictly for urgent messages and short polls.
Post regular bullet-point updates. Each message should include: current state, next action, and owner. This consistency eliminates ambiguity. Anyone joining mid-crisis can scroll up and instantly see what’s been done and what remains.
Automate alerting with simple scripts or built-in features in monitoring tools. Connect your uptime monitor to the chat platform via webhooks. One setup can trigger an alert, assign the on-call engineer, and start a timer for the first response.
Set up dashboards with key metrics—response time, resolution time, and downtime minutes. Share these routinely to improve performance. One group reduced average downtime from 60 to 30 minutes by reviewing the dashboard weekly and refining handoffs.
Use collaborative documents for live note-taking. Link to a shared file in every crisis channel. Assign one person to record decisions, one to update status, and one to tag next steps. This trio prevents overlap and ensures clear responsibility.
Run a mock data breach where one person emails a fake urgent alert. Observe who picks it up first and how quickly roles activate. Use a screen-recording tool to review the session. This process helps identify missed steps in the protocol.
Share a short report after each drill. Offer three points: a strength, a gap, and a fix. For example: “Communication remained clear, but we missed the escalation path. We’ll add a color-coded reminder banner to the protocol.” These quick wins generate momentum for real crises.
Teams that regularly update and practice their *playbook* handle crises faster. Keep the *playbook* a living document with clear protocols and routines to ensure effective team responses.
Teams often struggle to coordinate when working from various locations, which can make connecting different systems seem challenging. Smooth data flow increases...
Jan 05, 2026

Collaborating with team members in different countries often brings its own set of challenges, from juggling time zone differences to navigating diverse workplace...
Dec 07, 2025

Joining a company from a distance often brings unique challenges, especially when it comes to getting started with all the right tools and information. Clear...
Feb 03, 2026

Remote teams often manage conversations, video meetings, and document sharing across several platforms each day. Linking a virtual office platform with cloud storage...
Mar 11, 2026

Collaboration across multiple time zones often creates difficulties for teams who need to keep their code up to date and free from conflicts. Developers working remotely...
Mar 04, 2026

Easy access to reliable information helps teams spread across different locations resolve issues with greater speed and confidence. A thoughtfully organized knowledge...
Feb 06, 2026

Clear goals and effective communication help teams stay on track when working remotely. Define specific, measurable outcomes for each task so expectations remain...
Jan 05, 2026

Online businesses often manage their finances carefully, as recurring expenses can quickly add up. Monthly bills for subscriptions, unused software licenses, and...
Feb 17, 2026

Leading a team that spans several regions often brings unique challenges, from time zone differences and diverse cultural backgrounds to the reality of working in...
Nov 28, 2025

Teams working from different locations benefit when everyone has a clear plan and access to practical tools. Trying out new ideas with small, low-risk projects lets each...
Mar 13, 2026

Remote auditing presents unique opportunities to streamline your workflow and maintain efficiency, even when your team is spread across various locations. With the right...
Feb 21, 2026

Handling royalties and licensing across different countries often becomes complicated. Payments move through various currencies, while changing regulations and time...
Feb 24, 2026

Keeping track of digital credentials across different places can quickly become overwhelming, especially when juggling passwords for various platforms. Team members...
Mar 07, 2026

Teams working on complex projects frequently span multiple time zones, which can make real-time meetings challenging to schedule. Clear methods for organizing...
Jan 30, 2026

